DJ Reinforcement Learning System
A wireless ESP32-S2 sensor mesh feeds crowd-engagement data to a 2M-parameter GRU pretrained on ~3,000 DJ sets, with an RL head that adapts the next-song recommendation to live audience reaction.
Premise
A DJ is faced with an impossible amount of information to sift through. With roughly 475 million songs across Spotify and SoundCloud combined, and a curated DJ library that easily exceeds 1,000 tracks, it is hard to pay attention to the crowd’s reaction and pick the next song.
This project uses deep learning and reinforcement learning to traverse that maze on the DJ’s behalf. A wireless sensor mesh measures crowd engagement; a sequence model trained on real DJ sets proposes the next song; an RL head nudges that proposal based on what the crowd just did. The algorithm exploits, the musician explores.
What it actually looks like
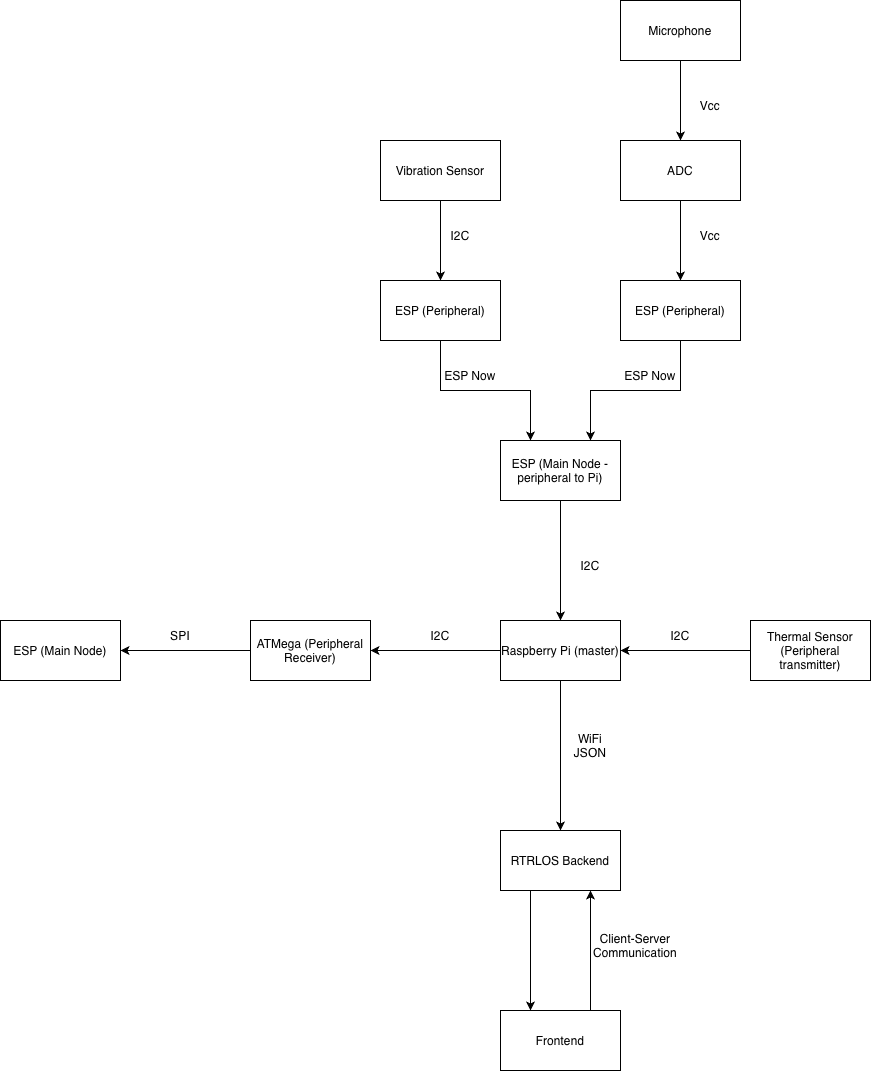
Sensor mesh (Chris)
Two peripheral packs, each a UM FeatherS2 (ESP32-S2) with a sensor and a LiPo battery, deployed wirelessly across the venue:
- Environmental (BME680): ambient temperature, humidity, pressure, VOC. All three move with crowd exertion. I²C to the FeatherS2.
- Audio (MAX9814): a microphone with automatic gain control. Sampled over a 50 ms window; min/max → ADC → calibrated decibel value. Required attenuation tuning on the ESP’s 12-bit ADC to avoid clipping the bias-shifted output.
Both packs broadcast over ESP-NOW to a single controller FeatherS2. The controller’s callback is deliberately tiny — flag-set only — because we previously bricked three FeatherS2 boards stacking heavier work in the callback alongside I²C.
Raspberry Pi (mine)
The Pi is the I²C master and the WiFi bridge. It pulls data from the controller ESP and from a thermal camera (calculating per-frame motion as the Frobenius norm of the consecutive-frame difference matrix), packages everything into JSON, and sends it to the Mac. It also pushes selected fields over I²C to the ATMega328PB, which drives the LCD — the bare-metal-C complexity requirement for the course.
RTRLOS — the orchestrator (mine)
RTRLOS stands for “Real-Time Reinforcement-Learning Operating
System.” It is, charitably, none of those things: not real-time, not
pre-emptive, not using a scheduler we wrote in this class. It is built on
Python’s asyncio and threading primitives,
which give us an event-driven loop and context-switching.
The architectural inspiration is GoLang’s parallelism idiom:
share memory by communicating, not the other way around. We
model channels with asyncio.Queue and the Pi-to-Mac pipe is
a long-lived WebSocket connection rather than shared mutable state.
The model
Two stages, mutually exclusive and chained:
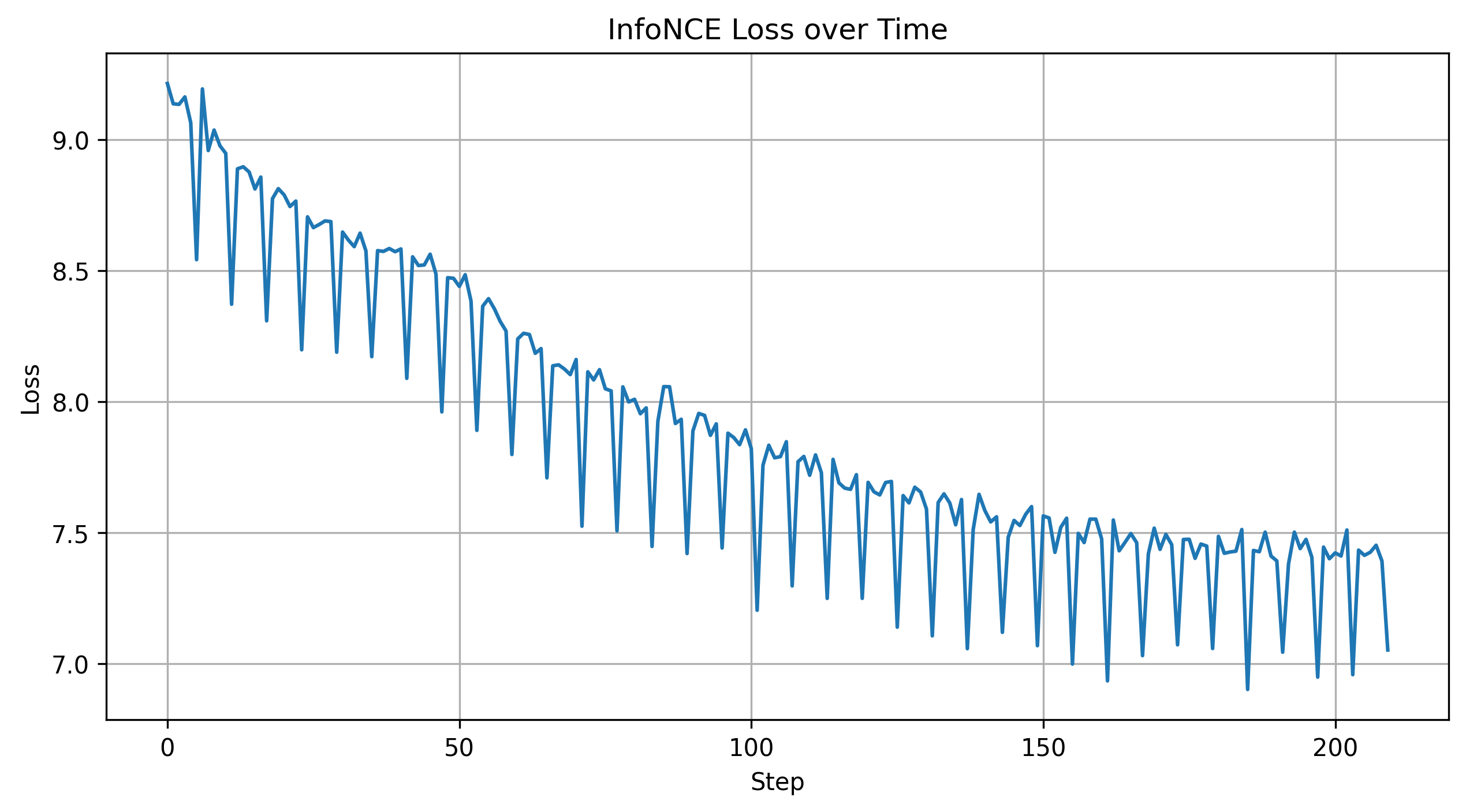
- Pretraining (offline). A custom web-scraper collected ~3,000 DJ sets. After preprocessing — trackname normalisation, audio-metadata extraction, embedding lookup — the corpus became a sequence-prediction dataset: given the last K songs, predict the next. We trained a small 2 M-parameter GRU (1,799,552 parameters) on next-song-in-sequence loss. Done before the semester started.
- Reinforcement-learning head (online). A small MLP
sitting on top of the GRU’s latent. It takes
[of_dx, of_dy, tof_mm, thermal_avgC, audio_db, …]+ the current sequence state and outputs a nudge vector. The RL signal is crowd movement after a song change. The frozen GRU contributes structure; the RL head contributes adaptation.
A simple in-memory vector database holds song embeddings; the inference step finds nearest-neighbour candidates to the predicted vector and ranks them. For an MVP-stage prototype with ~1,000 songs this is sufficient; a production version would swap in a real vector store.
What changed during the build
Almost all of the original hardware plan changed. The original block diagram had a single ATMega328PB at the centre, talking UART up to the Mac. The MVP demo inverted that: the Pi became the centre, the ATMega moved to the LCD edge, and UART became WiFi/JSON. The reasons were boring — sensor stack on the ATMega was prohibitively register-heavy for the parts we had — but the lesson was useful: simplify the data streams. Most of our debugging time was spent on protocol crossings (I²C ↔ ESP-NOW ↔ WiFi), not on application logic.
What I’d build next
- Better playback. The current system recommends a single next track. The interesting version overlaps stems — mix acapellas onto instrumentals, beat-match in software — so the “recommendation” is a transition, not a track.
- Bigger pretraining corpus & richer features. 3K sets and metadata-only embeddings were a starting point; raw audio embeddings (CLAP, Audio MAE) would let the model reason about timbre and energy directly.
- Off-board the thermal camera. Today it’s I²C to the Pi, which means the Pi sits where the camera sits. Moving the camera onto its own ESP peripheral pack gets it overhead, where it wants to be.
Built with Chris Spletzer for ESE 519 at UPenn (Fall 2025). Full report and demo video linked above.