Khronos
A Type II exovisor for WebAssembly: language-level sandbox + exokernel-style capability gating + a multi-tenant-safe data-parallel path. ~5K lines of Rust, denser than every runtime we benchmarked it against.
Abstract
We present Khronos, a runtime that combines WebAssembly’s language-level sandbox with exokernel-style capability gating and scheduler-mediated user-level parallelism. We call this combination a Type II exovisor: an ordinary host-OS process that multiplexes operating-system resources among mutually untrusted WebAssembly tenants through a small, tiered, capability-gated import surface.
Khronos exposes only ~74 named host entry points to a tenant module, in
contrast to the ~300 syscalls reachable from a Linux container, and runs
each invocation in a fresh sandboxed store with fuel-based instruction
accounting and epoch-based wall-clock deadlines. To support compute-heavy
workloads typical of regulated-data flows, Khronos additionally provides a
multi-tenant-safe data-parallelism path built on the WebAssembly threads
proposal: tenant code uses pthread_create unchanged, and a
custom wasi:thread-spawn handler dispatches workers onto a
bounded Rayon pool with per-isolate trap containment.
Across matrix multiply, k‑means, and SVD power-iteration workloads, Khronos achieves up to 6.7× speedup on four cores while remaining ~0.08 MiB per tenant isolate — an order of magnitude denser than vanilla Wasmtime and roughly 20× denser than Docker. We argue that this combination — WebAssembly sandboxing, exokernel-style capabilities, and shared-memory data parallelism — defines a usable cloud architecture for short, bursty, multi-tenant compute over regulated data.
The problem
Multi-tenant cloud compute trades off three things: isolation strength (one tenant cannot affect another), tenant density (how many independent guests fit per host), and compute throughput (how much real work each guest gets to do).
- Containers chose density at the price of isolation — one shared Linux kernel, ~300-syscall attack surface.
- Microvirtual machines (Firecracker) chose isolation at the price of density — a full guest-kernel image per tenant.
- Browser-style isolate runtimes (Cloudflare Workers) chose density and isolation at the price of throughput — ruling out compiled native-style code for languages other than JavaScript.
WebAssembly opens a fourth point. It is structurally a sandbox: bounds-checked linear memory, structured control flow, and only declared imports leave the sandbox. Host code owns the import table — therefore it owns the abstraction surface. Khronos turns that observation into a system.
Architecture
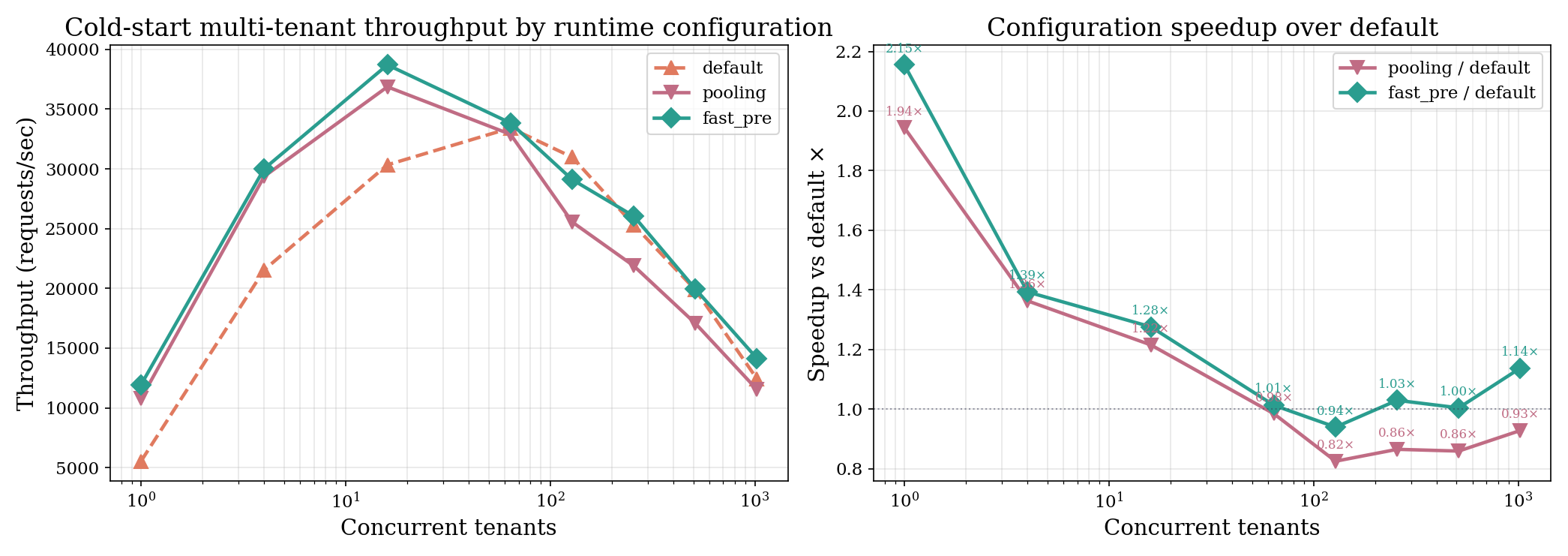
sfib(20). The fast-path
InstancePre peaks at ~41K req/s on the same workload as
vanilla Wasmtime’s 104K, — a deliberate trade against the
multi-tenant safety properties below.
Tiered, capability-gated import surface
Every host-reachable name is classified into one of six tiers. Tiers 1,
1′, and 2 are universal — any C++ runtime needs them to start
up. Tiers 2′ (WASI-NN inference), the intrinsic tier
(data-parallel MAP, REDUCTION), and Tier 3
(filesystem and networking syscalls) are gated per-tenant by a
CapabilitySet flag, checked at module instantiation
time — before any tenant code runs.
| Tier | Examples | Count |
|---|---|---|
| 1 (lang. runtime) | _Znwm, __cxa_throw | 8 |
| 1′ (WASI preview1) | proc_exit, fd_write | 13 |
| 2 (safe builtins) | memcpy, sin, pow | ~25 |
| 2′ (WASI-NN) | wasi_nn_load, wasi_nn_compute | 5 |
| Intrinsic | MAP, REDUCTION, CILK_REDUCE_* | 4 |
| 3 (cap-gated) | __syscall_openat, __syscall_socket | ~20 |
| Total surface | ~74 |
For comparison: a Linux container’s default seccomp allowlist exposes ~300 syscalls; a bare Firecracker microVM exposes ~300+ on top of ~40 host syscalls. A smaller surface is a smaller correctness-proof target. The implementation cost of capability gating is roughly 200 LOC for the resolver plus 100 for the gate check.
Multi-tenant isolation: per-Runtime engine, per-request store
WebAssembly’s isolation primitive is the Store. Two
stores in the same process share no mutable wasm-level state. Khronos
constructs one Engine per Runtime (process) and
one Store per request. The Engine is shared
across tenants by default in single-threaded mode, but in parallel mode
each invocation gets its own Engine — so bumping the
epoch to abort one tenant’s workers cannot affect any other tenant.
Two resource counters bound the work: a fuel counter
(instruction-count quota) decremented on every basic-block back-edge, and
a wall-clock deadline enforced through epoch interruption,
where a background ticker bumps the engine’s epoch every millisecond.
A Store whose deadline has passed traps on the next loop
back-edge or function entry.
Data parallelism, multi-tenant safe
Wasmtime’s Store is !Sync: it cannot be
shared across threads. Three ways exist to reconcile this with parallel
guest workers; Khronos picked wasm-threads with shared memory:
each worker gets its own Store, but they all bind the same
SharedMemory. There is no copy. The guest’s
pthread_create does the work-splitting; the host provides
only the spawn protocol.
The upstream wasmtime-wasi-threads handler calls
std::process::exit(1) on any worker trap or panic — for
a multi-tenant runtime, this is fatal: one tenant’s malformed binary
would take down every other tenant. Khronos therefore registers its own
wasi:thread-spawn handler with three properties:
- No process exit on worker errors. Every spawned worker
runs inside
std::panic::catch_unwind. A trap or panic produces a caughtErr; we set the per-isolateaborted: AtomicBool, stash the trap message, and bump the engine’s epoch deadline through to overshoot any in-flight worker. The host process keeps running; other tenants on other isolates have their own engines and are entirely unaffected. - Workers run on Rayon’s pool. Bare
std::thread::spawnwould let N tenants × M workers each blow past the host’s thread budget. Rayon’s global pool hasrayon::current_num_threads()workers; fan-out across all isolates is bounded by that ceiling. - Per-isolate worker-store pool. The first
≤
Nthreadsspawns of an isolate’s lifetime build a worker slot (Store + Instance + cachedwasi_thread_startTypedFunc + per-store__stack_pointerglobal) — the cold cost. Every subsequent spawn checks out an existing slot, resets per-call state (stack pointer reset to 1 MiB, fuel refilled, epoch deadline bumped), callswasi_thread_start, and returns the slot to the pool. Cold spawn costs hundreds of microseconds; warm spawn costs a few.
Evaluation
Tenant density
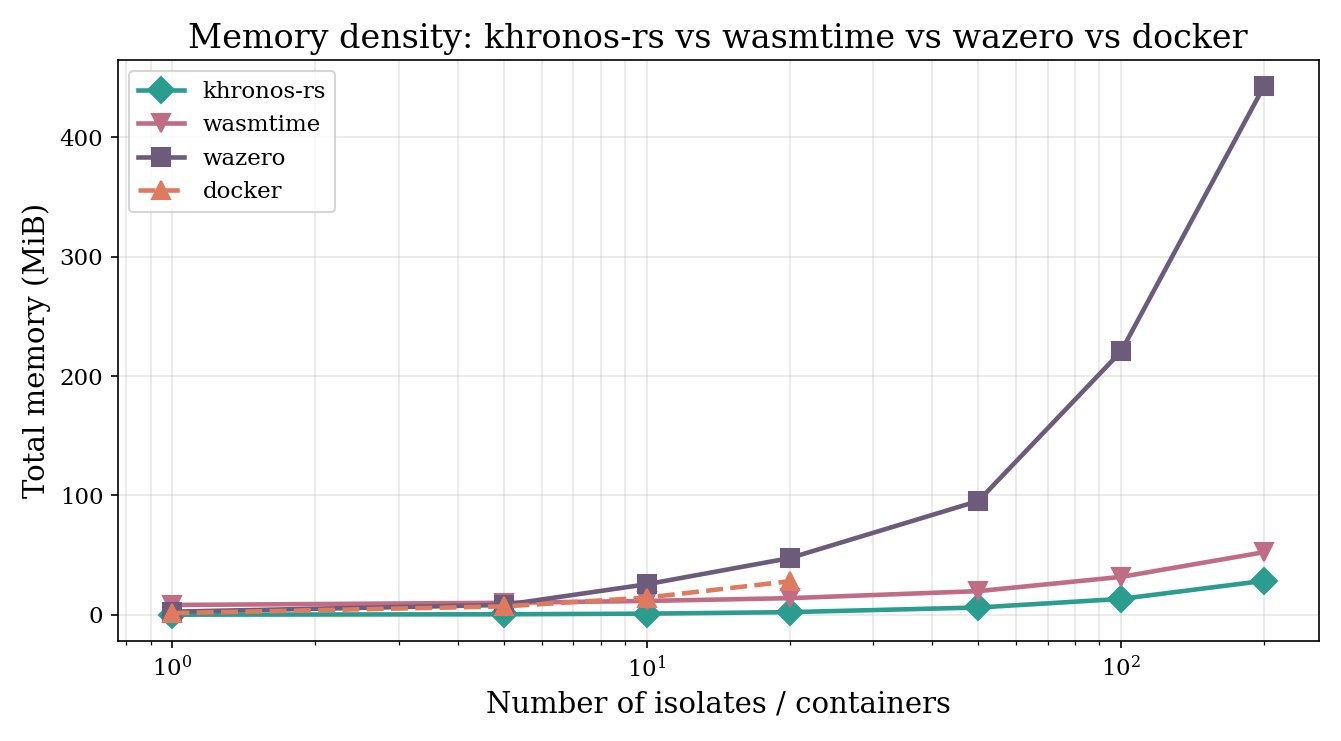
At N = 200 live isolates, the marginal cost per isolate is:
| Runtime | Per-isolate cost |
|---|---|
| khronos-rs | 0.08 MiB |
| Wasmtime (vanilla) | 0.27 MiB |
| Docker | ~1.40 MiB |
| wazero | 2.22 MiB |
Khronos is approximately 3× denser than vanilla Wasmtime and roughly 18× denser than Docker. The Khronos number translates to ~200,000 tenants per 16 GiB host, against Docker’s ~11,500 on the same VM.
Multi-tenant throughput
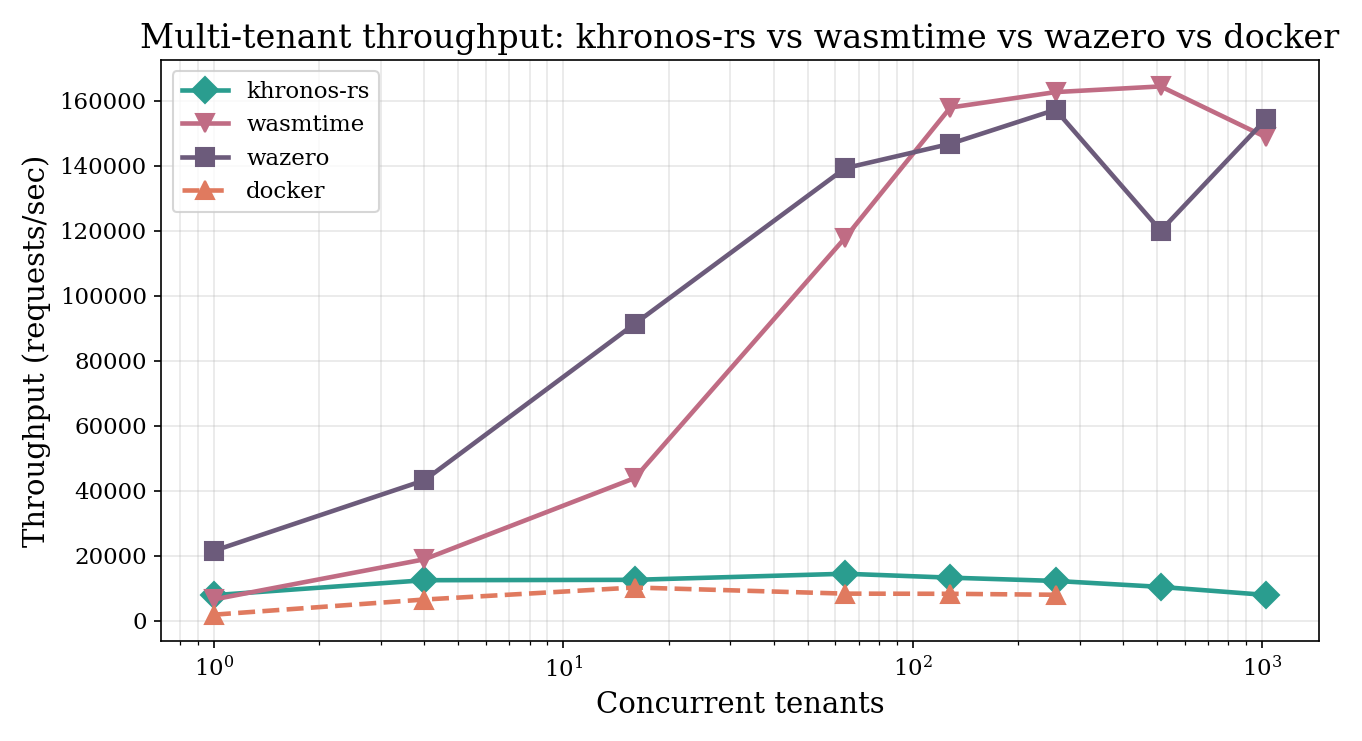
sfib(20) against their own private isolate.
On the 4-vCPU box, peak throughput is ~38K req/s for Khronos at
N=16, vs. Wasmtime’s ~104K at N=512.
Khronos’s invoke path has per-call overhead —
capability checks, intrinsic linker registration, fuel and epoch reset
— that does not amortise on a one-call-per-isolate burst test.
Khronos exposes two opt-in configurations (pooling allocator + fast-path
InstancePre) that close most of the gap.
Parallel intrinsics
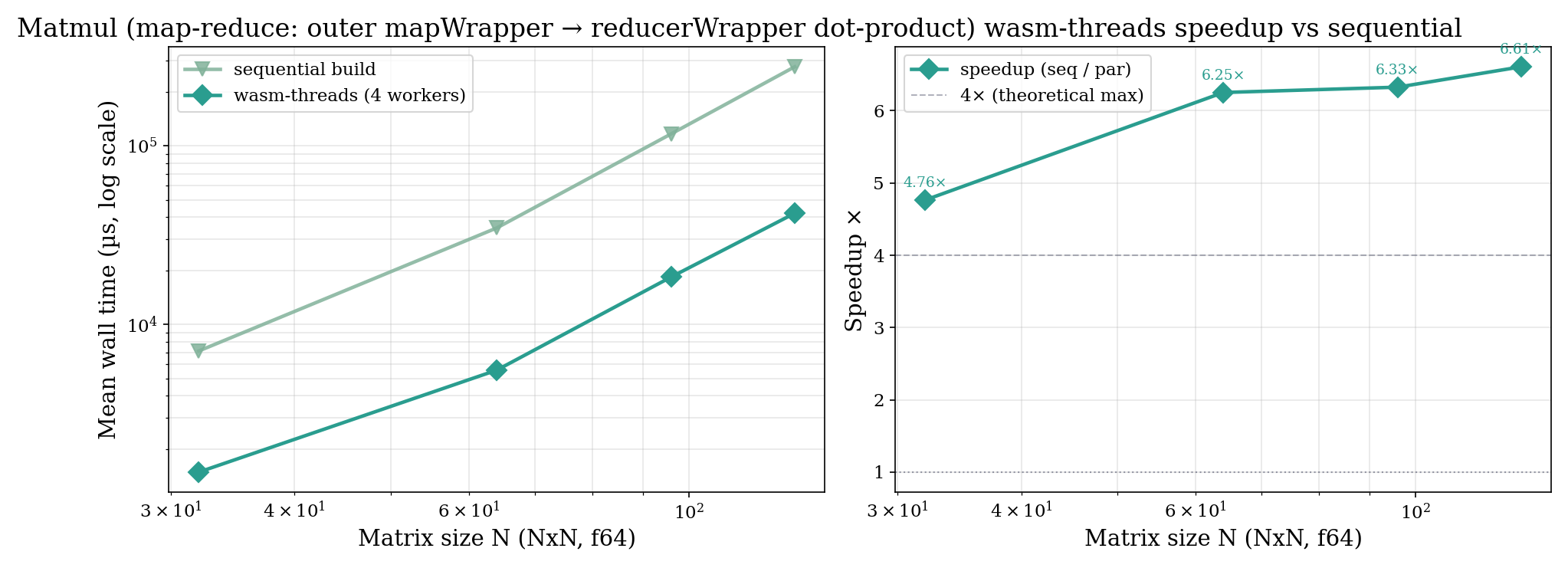
| N | seq | wasm-threads | speedup |
|---|---|---|---|
| 32 | 6.7 ms | 1.3 ms | 5.2× |
| 64 | 34.8 ms | 5.8 ms | 6.0× |
| 96 | 115.7 ms | 17.5 ms | 6.6× |
| 128 | 276.0 ms | 41.2 ms | 6.7× |
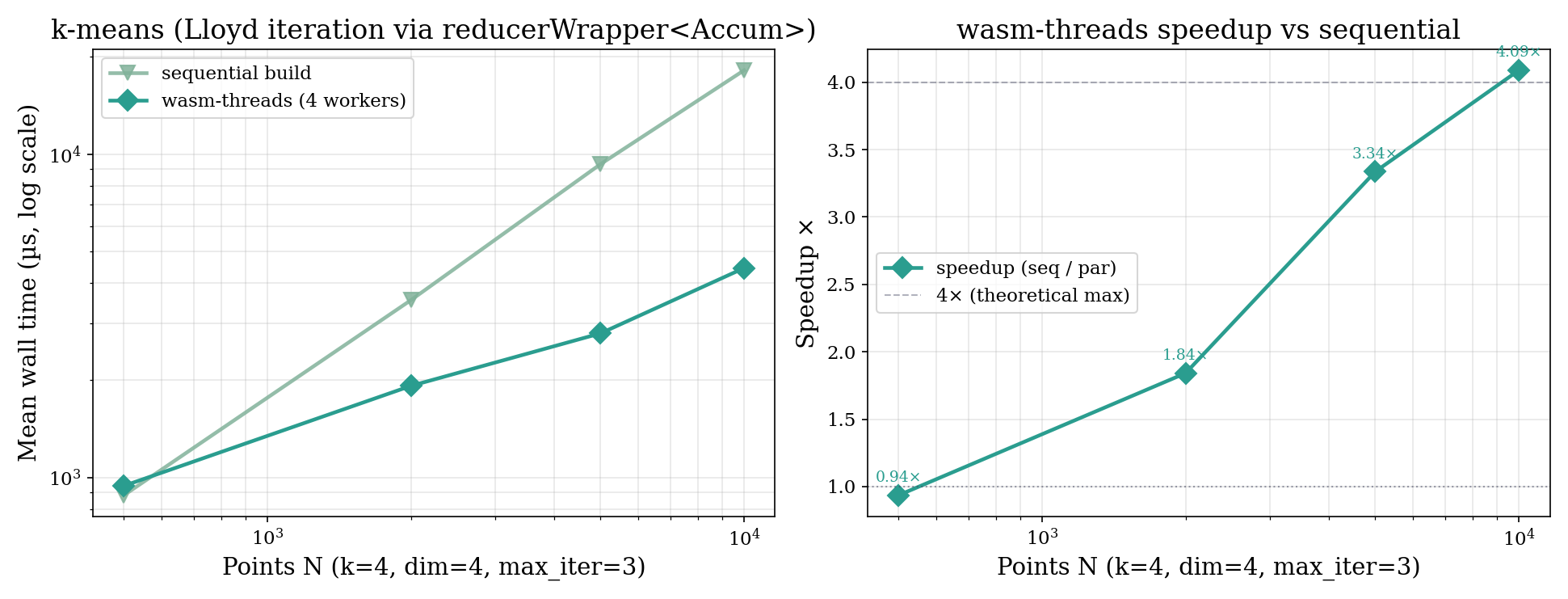
The 6.7× at N = 128 exceeds the 4× implied by four workers because per-thread accumulators stay hot in L1 and the sequential build cannot benefit from the same locality.
The honest limitations
- Per-call invocation overhead. The 38K req/s peak vs. Wasmtime’s 104K is largely attributable to per-call linker registration of intrinsics and per-call fuel/epoch reset. Both can be amortised across calls.
- Fixed worker count. Khronos hardcodes Nthreads=4 in the guest wrapper to match the typical 4-vCPU deployment. An adaptive thread-count or a runtime-supplied variable is straightforward future work.
- Fork-join only. Workers atomic-waiting on each other can deadlock if Rayon’s pool fills up. Cilk-shaped MAP/REDUCTION workloads do not trigger this; barrier-style workloads would.
- Side-channel posture. Khronos relies on WebAssembly’s structural isolation and adds wall-clock limits to bound timing-channel signal — it does not eliminate microarchitectural side channels. Coordinated host-OS mitigations would be required.
Implementation
Khronos is implemented in Rust (~5,000 lines), split across three crates
(runtime, server, cli). The HTTP
server uses axum with SQLite for tenant metadata and exposes
admin endpoints (tenant + API key creation), tenant endpoints (module
upload, invoke, SSE event stream), and a Prometheus
/metrics endpoint. The full benchmark harness lives in
benchmark/ and reproduces every plot in the paper with a
single shell command.
Co-authored with Ajax Li (UPenn). Thank you to the architecture group at Penn for early feedback.